MLOps on AWS: Streamlining Data Ingestion, Processing, and Deployment


Audio : Listen to This Blog.
In this blog post, we will explore a comprehensive architecture for setting up a complete MLOps pipeline on AWS with a special focus on the emerging field of Foundation Model Operations (FMOps) and Large Language Model Operations (LLMOps). We’ll cover everything from data ingestion into the data lake to preprocessing, model training, deployment, and the unique challenges of generative AI models.
1. Data Ingestion into the Data Lake (Including Metadata Modeling)
The first step in any MLOps pipeline is to bring raw data into a centralized data lake for further processing. In our architecture, the data originates from a relational database, which could be on-premise or in the cloud (AWS RDS for Oracle/Postgres/MySQL/etc). We use AWS Database Migration Service (DMS) to extract and replicate data from the source to Amazon S3, where the data lake resides.
Key points:
- AWS DMS supports continuous replication, ensuring that new data in the relational database is mirrored into S3 in near real-time.
- S3 stores the data in its raw format, often partitioned by time or categories, ensuring optimal retrieval.
- AWS Glue Data Catalog is integrated to automatically catalog the ingested data, creating metadata models that describe its structure and relationships.
The pipeline ensures scalability and flexibility by using a data lake architecture with proper metadata management. The Glue Data Catalog also plays a crucial role in enhancing data discoverability and governance.
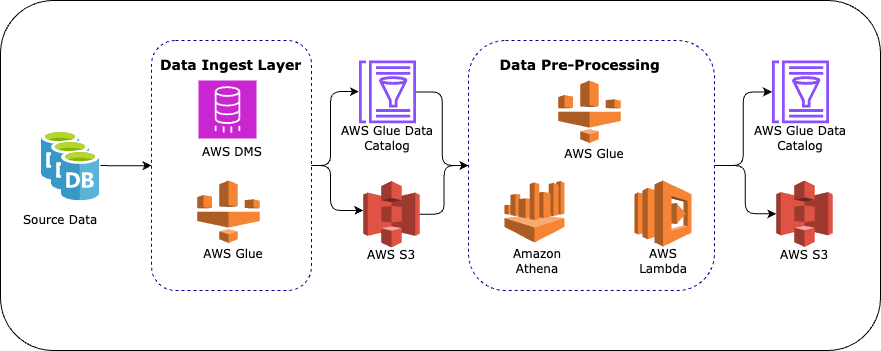
2. Data Pre-Processing in AWS
Once the data lands in the data lake, it undergoes preprocessing. This step involves cleaning, transforming, and enriching the raw data, making it suitable for machine learning.
Key AWS services used for this:
- AWS Glue: A fully managed ETL service that helps transform raw data by applying necessary filters, aggregations, and transformations.
- AWS Lambda: For lightweight transformations or event-triggered processing.
- Amazon Athena: Allows data scientists and engineers to run SQL queries on the data in S3 for exploratory data analysis.
For feature management, Amazon SageMaker Feature Store stores engineered features and provides consistent, reusable feature sets across different models and teams..
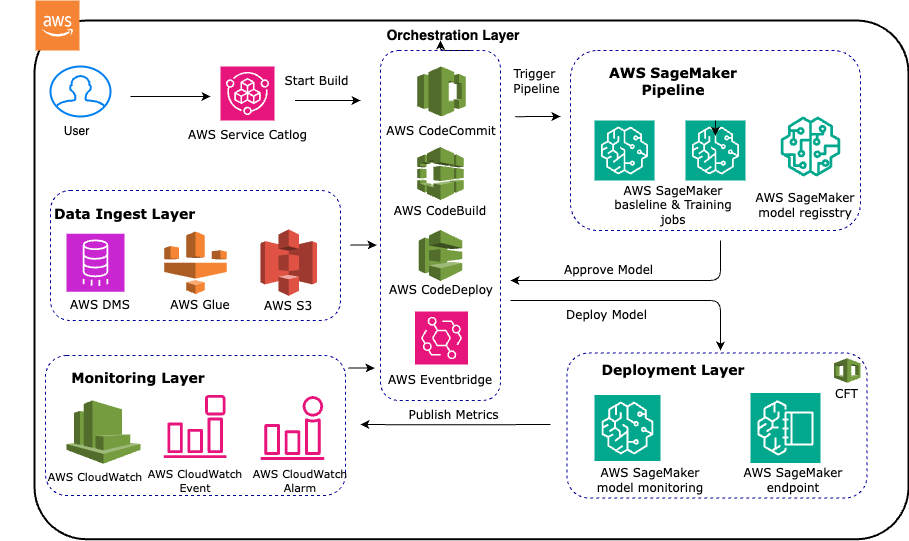
3. MLOps Setup to Trigger Data Change, ML Model Change, or Model Drift
Automating the MLOps process is crucial for modern machine learning pipelines, ensuring that models stay relevant as new data or performance requirements change. In this architecture, MLOps is designed to trigger model retraining based on:
- New data availability in the data lake (triggered when data changes or is updated).
- Model changes when updates to the machine learning algorithm or training configurations are pushed.
- Model drift when the model’s performance degrades due to changing data distributions.
Key services involved:
- Amazon SageMaker: SageMaker is the core machine learning platform that handles model training, tuning, and deployment. It can be triggered by new data arrivals or model performance degradation.
- Amazon SageMaker Model Monitor: This service monitors deployed models in production for model drift, data quality issues, or bias. When it detects deviations, it can trigger an automated model retraining process.
- AWS Lambda & Amazon EventBridge: These services trigger specific workflows based on events like new data in S3 or a drift detected by Model Monitor. Lambda functions or EventBridge rules can trigger a SageMaker training job, keeping the models up to date.
By leveraging this automated MLOps setup, organizations can ensure their models are always performing optimally, responding to changes in the underlying data or business requirements.
4. Deployment Pipeline
After the model is trained and validated, it’s time to deploy it for real-time inference. This architecture’s deployment process follows a Continuous Integration/Continuous Deployment (CI/CD) approach to ensure seamless, automated model deployments.
The key components are:
- AWS CodePipeline: CodePipeline automates the build, test, and deployment phases. Once a model is trained and passes validation, the pipeline pushes it to a production environment.
- AWS CodeBuild: This service handles building the model package or any dependencies required for deployment. It integrates with CodePipeline to ensure everything is packaged correctly.
- Amazon SageMaker Endpoints: The trained model is deployed as an API endpoint in SageMaker, allowing other applications to consume it for real-time predictions. It also supports multi-model endpoints and A/B testing, making deploying and comparing multiple models easy.
- Amazon CloudWatch: CloudWatch monitors the deployment pipeline and the health of the deployed models. It provides insights into usage metrics, error rates, and resource consumption, ensuring that the model continues to meet the required performance standards.
- AWS IAM, KMS, and Secrets Manager: These security tools ensure that only authorized users and applications can access the model endpoints and that sensitive data, such as API keys or database credentials, is securely managed.
This CI/CD pipeline ensures that any new model or retraining job is deployed automatically, reducing manual intervention and ensuring that the latest, best-performing model is always in production.
5. FMOps and LLMOps: Extending MLOps for Generative AI
As generative AI models like large language models (LLMs) gain prominence, traditional MLOps practices must be extended. Here’s how FMOps and LLMOps differ:
Data Preparation and Labeling
- For foundation models, billions of labeled or unlabeled data points are needed.
- Text-to-image models require manual labeling of
- For LLMs, vast amounts of unlabeled text data must be prepared and formatted consistently.
Model Selection and Evaluation
- FMOps introduce new considerations for model selection, including proprietary vs. open-source models, commercial licensing, parameter count, context window size, and fine-tuning capabilities.
- Evaluation metrics extend beyond traditional accuracy measures to include factors like coherence, relevance, and creativity of generated content.
Fine-Tuning and Deployment
- FMOps often involve fine-tuning pre-trained models rather than training from scratch.
- Two main fine-tuning mechanisms are deep fine-tuning (recalculating all weights) and parameter-efficient fine-tuning (PEFT), such as LoRA.
- Deployment considerations include multi-model endpoints to serve multiple fine-tuned versions efficiently.
Prompt Engineering and Testing
- FMOps introduces new roles like prompt engineers and testers.
- A prompt catalog is maintained to store and version control prompts, similar to a feature store in traditional ML.
- Extensive testing of prompts and model outputs is crucial for ensuring the quality and safety of generative AI applications.
Monitoring and Governance
- In addition to traditional model drift, FMOps require monitoring for issues like toxicity, bias, and hallucination in model outputs.
- Data privacy concerns are amplified, especially when fine-tuning proprietary models with sensitive data.
Reference Architecture
Conclusion
The integration of FMOps and LLMOps into the MLOps pipeline represents a significant evolution in how we approach AI model development and deployment. While the core principles of MLOps remain relevant, the unique characteristics of foundation models and LLMs necessitate new tools, processes, and roles.
As organizations increasingly adopt generative AI technologies, it’s crucial to adapt MLOps practices to address the specific challenges posed by these models. This includes rethinking data preparation, model selection, evaluation metrics, deployment strategies, and monitoring techniques.
AWS provides a comprehensive suite of tools that can be leveraged to build robust MLOps pipelines capable of handling both traditional ML models and cutting-edge generative AI models. By embracing these advanced MLOps practices, organizations can ensure they’re well-positioned to harness the power of AI while maintaining the necessary control, efficiency, and governance.